[Network] HTTP 컨텐츠 협상
본 내용은 MDN HTTP 컨텐츠 협상을 보고 공부, 정리한 내용입니다.
컨텐츠 협상
모든 리소스에는 고유한 URL이 존재한다. 클라이언트는 이 URL을 통해 리소스에 접근하고, 서버는 그에 대응하는 리소스를 제공한다. 리소스는 타입, 압축 방식 등에 따라서 다른 URL을 갖는데, 이를 representation이라 한다. 서버가 클라이언트의 요청에 알맞는 representation을 제공할 때 컨텐츠 협상이 진행되며, 컨텐츠 협상은 여러 방식이 존재한다.
가장 적당한 representation을 찾는 방법에는 두 가지가 있다.
-
Server-driven content negotiation
클라이언트가 수용할 수 있는, 혹은 선호하는 리소스의 상태를 HTTP 헤더에 담아서 서버에게 알려주는 방식.가장 표준적으로 많이 쓰이는 방식이다.
-
Agent-driven content negotiation
HTTP 응답 코드 300, 혹은 406을 이용하는 방식. fallback 매커니즘으로 사용되는 방식이다.
Server-driven content negotiation
클라이언트가 HTTP 요청 헤더를 통해 원하는 representation을 알려주고, 서버는 이를 힌트로 삼아 내부 컨텐츠 협상 알고리즘을 통해 representation을 선택한 후 클라이언트에게 응답하는 방식이다.
이 때 서버의 내부 컨텐츠 협상 알고리즘은 표준화된 것이 아니며, 서버가 어떻게 구현하느냐에 달렸다.
HTTP /1.1 표준에서는 컨텐츠 협상과 관련된 요청 헤더 (Accept, Accept-Charset, Accept-Encoding, Accept-Language) 를 정의하고 있다. User-Agent는 이 분류에 포함되지는 않지만, 서버 측에서 이 헤더도 고려하여 컨텐츠 협상하는 경우도 있다. 서버는 Vary 헤더를 통해 컨텐츠 협상에 어떤 HTTP 요청 헤더를 기준으로 사용했는지를 알려준다. 이 덕분에 캐시도 최적화되어 동작할 수 있다.
참고로 최근에 클라이언트 힌트라고 불리는 헤더들이 서버에게 더 많은 클라이언트 정보를 전달해 주기 위해 실험적으로 사용되고 있다. 이 헤더들은 클라이언트가 사용하고 있는 기기에 대한 정보를 전달하는 역할을 한다. (모바일 기기 vs 데스크탑)
Server-driven 방식의 단점
Server-driven content negotiation는 가장 널리, 일반적으로 사용되지만 몇 가지 단점을 갖고 있다.
브라우저에 대한 정보 부족
기본적으로 서버는 클라이언트의 상태를 모르고 있기 때문에, 서버가 선택한 representation이 클라이언트에게 적합할지 100% 확신할 수 없다.
보안적인 측면
클라이언트가 제공하는 정보는 장황한 면이 있어 서버가 이를 해석하기에 비용이 든다. (HTTP /2에서 헤더 압축을 통해 이러한 단점이 완화되기는 했다.)
또한 사생활 침해에 대한 위협도 존재한다. (HTTP fingerprinting = HTTP 헤더 정보를 보고 원격 컴퓨터의 OS를 알아내거나, 원격 애플리케이션의 버전이나 사용중인 프로토콜을 알아내는 기법을 말한다.)
캐시 성능
클라이언트가 요청한 리소스에 대한 몇 개의 representation이 전송되므로, shared cache의 경우 캐시 효율성이 떨어지고 서버 구현은 좀 더 복잡해진다.
컨텐츠 협상에 사용되는 HTTP 헤더
Accept
컨텐츠의 타입 (MIME) 에 대한 내용이다.
- 예시
Accept: text/html Accept: image/png, image/gif
Accept-Charset
클라이언트가 이해할 수 있는 문자 인코딩 타입을 명시한다.
전통적으로 클라이언트의 위치에 따라 서로 다른 값을 설정하기 위해 사용되었다. (서부 유럽의 경우 ISO-8859, utf-8; q=0.7, *; q=0.7; 와 같이 설정되었다.)
현재는 utf-8 인코딩 방식이 잘 작동되고, 선호되고 있으므로 클라이언트의 위치에 따라 서로 다른 값을 설정해야하는 이유가 줄어들고 있다. 아울러 클라이언트의 정보를 최대한 덜 노출시키기 위해 최근 여러 브라우저들은 Accpet-Charset 헤더의 지원을 중단하고 있다.
Accept-Encoding
클라이언트가 수용할 수 있는 HTTP 압축 방식을 명시한다. 여러 압축 방식을 명시할 때는 q인자를 사용하여 우선순위를 나타낸다.
전송되는 데이터의 압축은 대역폭을 절약할 수 있는 좋은 방법이므로, 브라우저는 필수적으로 Accept-Encoding 헤더를 포함시켜 요청한다. 서버는 Accept-Encoding 헤더를 해석하여 그 압축 방법을 사용할 수 있는 능력이 있어야 할 것이다.
Accept-Language
클라이언트가 선호하는 언어 목록을 명시한다. 여러 언어를 명시할 때는 q인자를 사용하여 언어 간 선호 우선순위를 나타낸다.
사용자 에이전트(대게 브라우저)는 기본적으로 현재 사용자 인터페이스의 언어 설정값을 이용하여 Accept-Language값을 보내지만, 사용자가 기호에 맞는 언어를 선택할 수 있게끔 사이트 설계자는 대비를 할 필요가 있다. (사이트 상단 메뉴에 언어 탭을 만들어 두는 방법 등..)
만약 서버에서 클라이언트의 Accpet-Language 헤더에 맞는 representation을 제공할 수 없다면, 이론적으로는 응답코드 406 Not Accepted를 반환하지만, 보통 Accept-Language를 무시하고 다른 힌트에 맞는 representation을 제공한다.
(ex 번역본이 없는 영문으로 작성된 해외 사이트의 게시글 페이지를 요청 시, Accept-Language: ko 헤더는 무시될 수 있다.)
User-Agent
User-Agent는 요청을 보내는 브라우저를 명시한다. Product Tokens 와 comments 가 공백으로 구분된 문자열 형태이다.
Product Token은 [브라우저 이름/버전] 으로 구성되어 있다. Comment는 괄호 안에 적혀 있으며, 해당 브라우저가 속한 호스트의 운영체제 등의 내용이 포함된다.
1 | |
Vary
HTTP 응답 헤더의 한 종류로써 클라이언트가 제시한 여러 representation 조건 중 서버가 기준으로 선택한 헤더가 무엇인지를 알려주는 헤더이다. 이는 캐시와 밀접한 관련이 있는데, Vary헤더를 이용하여 사용자가 동일 리소스의 다른 representation을 원할 때 이전에 캐싱된 내용을 사용하는 것을 방지할 수 있다.
Vary: *; 는 서버가 클라이언트가 제시한 여러 representation 조건 이외의 다른 조건도 고려했음을 알린다. 즉, 이 헤더를 받은 클라이언트는 해당 리소스를 캐싱하지 않을 것이다.
Agent-driven content negotiation
Server-driven 컨텐츠 협상은 클라이언트가 더 정확한 정보를 제공하려 하면 할 수록 그에 비례하여 더 많은 헤더가 필요하고, 이는 곧 필요한 대역폭의 증가와 개인정보의 흔적이 인터넷상에 더 많이 남음을 의미한다. 이에 HTTP는 서버가 애매한 representation 조건을 마주했을 때, 유효한 여러 개의 리소스가 포함된 URL을 클라이언트에 넘겨 클라이언트가 이를 보고 특정한 representation을 선택하는 Agent-driven 컨텐츠 협상 방법을 지원하고 있다.
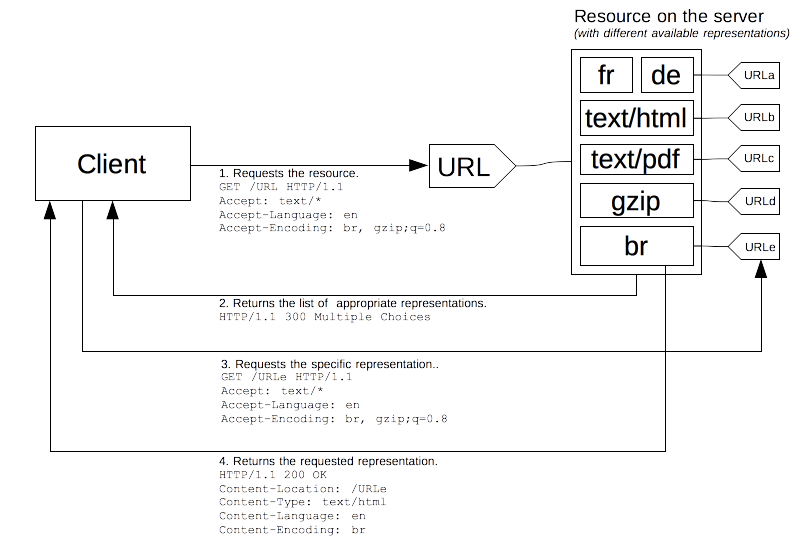
하지만 이 방법은 아직 문제점이 많다. 우선, HTTP가 공식적으로 서버가 응답하는 대체 리소스의 형식을 명시하지 않았다. 또한, 하나의 리소스를 받기 위해 요청/응답이 한 개 이상 필요하다는 점에서 리소스 효용성이 떨어진다는 단점도 존재한다.