[Network] HTTP 압축
본 내용은 MDN HTTP 압축를 보고 공부, 정리한 내용입니다.
HTTP에서 압축이 필요한 이유
전송하는 데이터의 양이 적을수록 그만큼 적은 대역폭으로 데이터 전송이 가능하다.
일반적으로, 웹 상에서 교환되는 데이터에는 여러 중복들이 존재한다.
(텍스트는 60% 정도, 이미지 및 비디오와 같은 미디어 데이터는 더 많은 중복이 존재한다.)
여러 브라우저, 서버가 압축 매커니즘을 잘 구현해 놓고 있으므로 개발자가 이를 직접 구현할 필요는 없다. 프론트엔드 개발자는 적절한 요청을, 백엔드 개발자는 요청에 대한 적절한 처리만 잘 구현하면 된다.
HTTP 데이터를 압축한다는 것은 HTTP 시작줄, 헤더, 본문 중 본문을 압축하는 것을 말한다.
HTTP 압축이 항상 긍정적인 결과를 낳는다는 오해는 없어야 한다.
단적인 예로, 대역폭이100Mbps가 넘어가는 네트워크 환경에서는 HTTP 압축을 통해 데이터를 보낼 때 절약되는 대역폭보다 데이터 압축 오버헤드가 더 클 수도 있다.
보통 HTTP 압축은 파일 포맷 압축 / HTTP 계층에서의 암호화 / HTTP 커넥션 사이에서의 압축 이렇게 3가지가 존재한다.
파일 포맷 압축
손실 압축
사용자가 알아채기 힘든 범위 내에서 이뤄지는 데이터의 일부 손실이 있는 압축을 말한다.
즉, 복원 데이터와 본래 데이터에 차이가 있다.
대표적으로 웹 상에서의 비디오, jpeg 이미지는 손실 압축이 사용된다.
무손실 압축
본래 데이터와 복원 데이터에 차이가 없도록 압축 - 복원하는 압축 방법이다.
이미지 중 gif, png 등이 무손실 압축을 사용한다.
HTTP 커넥션 압축
종단 간 압축
서버에서 HTTP 파일을 압축하여 전송하고, 클라이언트가 압축을 풀어서 사용자에게 제공하는 압축 방식이다.
클라이언트에서 Accept-Encoding 헤더로 압축 알고리즘을 지정할 수 있으며, 대표적으로 gzip이 있다.
서버는 요청에 Accept-Encoding 헤더를 보고 그에 맞는 압축 알고리즘으로 데이터를 압축한다. 그리고 응답 헤더에 Content-Encoding 헤더를 통해 클라이언트에게 해당 파일이 어떤 알고리즘으로 압축되었는지를 알려준다.
(브라우저는 Content-Encoding을 보고 그에 맞게 압축을 푼다.)
또한 서버가 Content-Encoding을 명시했다면, Vary 헤더에 Content-Encoding을 포함시켜서 응답해야한다.
Vary 헤더는 클라이언트가 캐시된 리소스를 사용할 때, 해당 리소스를 재사용해도 되는지를 판단하는 기준을 제시한다.
예를 들어, Vary: Content-Encoding 이 명시되어 있는 리소스가 gzip 포맷일 때, 클라이언트가 해당 리소스를 deflate로 요청한 상황이면 해당 캐시 리소스를 사용하지 못한다. (본 서버에 요청을 보내야 한다.)
Hop-by-hop 압축
hop-by-hop은 압축, 압축 해제가 서버, 클라이언트에서 일어나지 않고, HTTP 커넥션 중간의 노드 사이에서 일어난다.
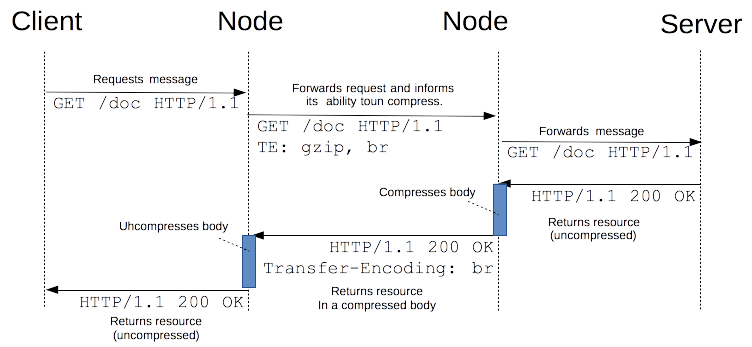
위 그림처럼, 요청 측의 노드가 TE 헤더로 원하는 압축 방식을 기술한다. 서버에서는 압축 없는 본 데이터를 담아 응답하고, 응답 측의 노드가 이전에 TE 헤더에 기술했던 방식으로 데이터를 압축 후 다음 노드에게 전달한다. 요청 측 노드가 해당 응답을 받으면 본 데이터로 복원한 뒤 클라이언트에게 전달한다.
Hop-by-hop 방식은 현재는 드물게 사용된다. TE 헤더와 Transfer-Encoding 헤더는 데이터를 청크 형태로 전달할 때 유용하므로 서버에서 응답해야할 데이터의 크기가 상당히 클 때 주로 사용된다.
참고로 청크 형태의 데이터는 말 그대로 데이터를 조각내어 일정 크기의 여러 개의 데이터로 나누어 전송하는 방법이다. 청크 형태의 데이터 전송은 보내고자 하는 데이터의 전체 길이를 몰라도 전송을 시작할 수 있다. 즉, output stream buffer에 전체 데이터를 쌓은 뒤 한번에 전송하지 않아도 되고, 수신 측도 input stream buffer에 청크 데이터들이 전부 모일 때 까지 기다릴 필요가 없다.
따라서 HTTP로 청크 데이터 전송 시 응답 헤더에 Content-length가 명시되지 않는다. 대신 본문에 각 청크 데이터의 길이와 데이터가 쌍으로 표기되어 클라이언트는 데이터의 길이를 보고 다음 줄의 내용을 그 길이만큼만 읽는 식으로 수신한다.
데이터의 길이가 0일 때, 클라이언트는 청크 데이터 수신을 종료한다.
1 | |