[Algorithm] KMP 알고리즘
이 포스트에선 KMP 알고리즘에 대해 다룬다.
처음 접하면 꽤 복잡한 알고리즘이다. 이에 아래 블로그 포스트를 보고 도움을 얻었고, 나름대로 이해한 내용을 정리하며 KMP에 대한 이해도를 한층 높여보고자 이 포스트를 작성하게 되었다.
https://bowbowbow.tistory.com/6
언제 사용되는 알고리즘인가?
우리가 흔히 접하는 웹 브라우저, PDF뷰어, MS word 등에서 제공하는 단어 찾기 기능은 KMP 알고리즘에 기반한다. 가장 쉽고 간단한 완전 탐색은 왜 사용하지 않을까?
항상 그렇듯, 시간복잡도를 고려해보지 않을 수 없다. 완전 탐색으로 부분 문자열을 찾아내는 방법을 생각해보자. 길이가 N인 문자열에서 길이가 M인 부분 문자열을 찾을 때, 완전 탐색으로 찾는다면 시간복잡도는 어떻게 될까?
문자열을 N-M+1 번 선형 탐색하며 각 탐색마다 부분 문자열 길이 M만큼 비교하므로, 시간복잡도는 O((N-M+1) * M), 대략 O(N*M) 라고 볼 수 있다. (일반적으로 N이 M보다 훨씬 크기 때문)
이 경우 N혹은 M이 증가할수록 문제가 심각해진다. 한 번 탐색할 때 소요시간이 비약적으로 증가하기 때문이다. 물론 이런 경우가 흔하지는 않겠지만, 사용자가 어떤 페이지에서 어떤 단어를 찾을지 모르기 때문에 가볍게 넘길 수 있는 예외 상황은 아니다.
KMP 알고리즘 동작 예시
그렇다면 KMP 알고리즘은 완전탐색과 무엇이 다르길래 어떤 상황에서든 빠르게 탐색이 가능할까?
KMP알고리즘은 완전 탐색에서 등한시했던 문자열 탐색 중 일치했던 부분에 집중한다. 가벼운 마음으로 예시를 통해 천천히 살펴보자.
ABABACAB 에서 ABAC 를 찾는 상황을 예시로 삼았다.
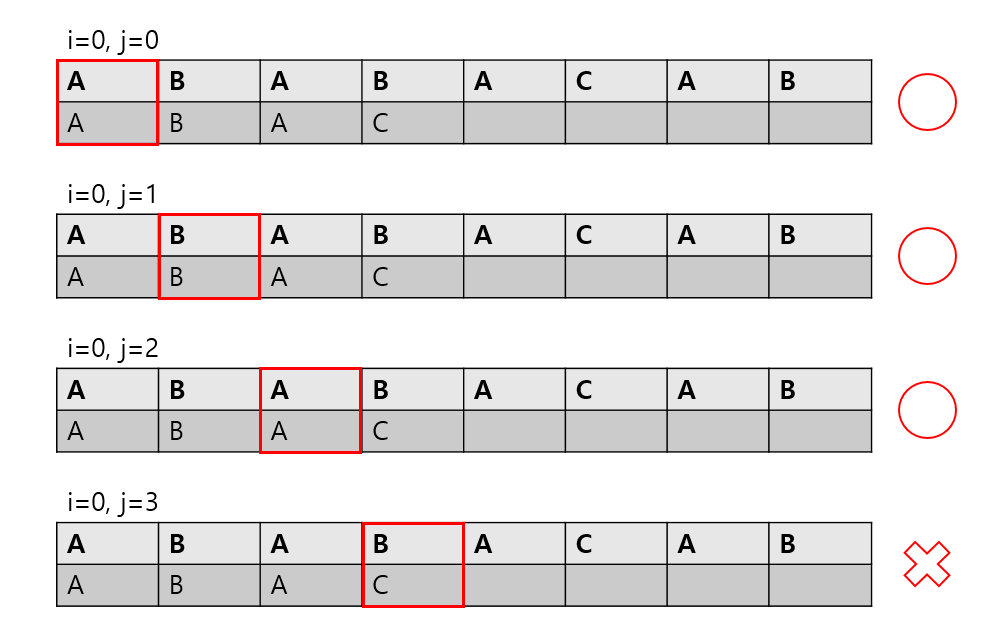

(i는 str의 인덱스, j는 부분 문자열의 인덱스이다.)
(str은 전체 문자열, pattern은 부분 문자열이다.)
(즉, str[i+j]와 pattern[j]를 비교하는 모습.)
보다시피 완전탐색에서는 ABA까지 일치한다는 정보를 버린다. 이 정보를 어떻게 살려낼 수 있을까?
이를 위해, KMP 알고리즘에선 pattern의 접두사와 접미사에 대한 정보를 저장하는 pi배열을 사용한다.
pi[k]는 pattern의 0~k 인덱스로 구성된 부분 문자열에서, 동일한 접두사와 접미사의 최대 길이를 의미한다. 말로 설명하니 굉장히 이해하기 어려운데, 아래 그림을 보면 그리 어려운 내용은 아니다.
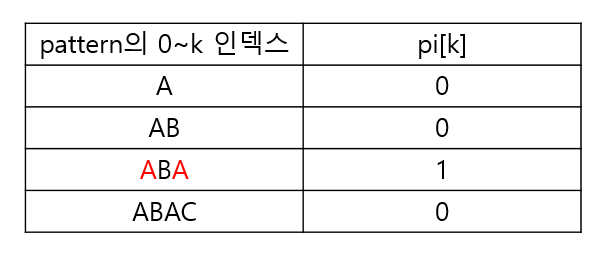
pattern ABAC를 찾는 위 예시를 이어서 살펴보자.
ABA까지 비교한 상황에서, str[3]과 pattern[3]을 비교하게 된다. str[3]은 B, pattern[3]은 C이므로 서로 다르다. 이 때, 단순히 pattern을 한 칸 뒤로 밀어서 비교하지 말고 (완전탐색에서 사용한 방법), 이전까지의 부분 문자열(ABA)의 접미사 자리(2번째 A)에 접두사(0번째 A)를 위치시키면 바로 str[3]와 pattern[1]을 비교할 수 있다.
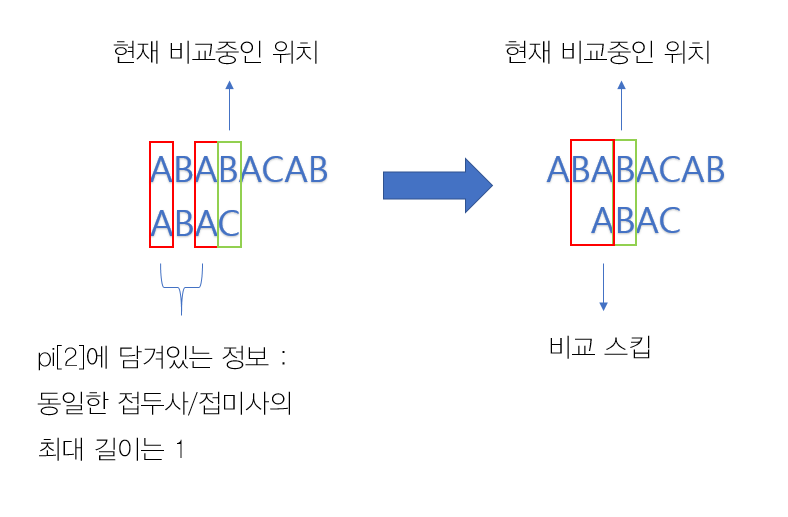
이 개념을 코드로 구현한 것이 아래 내용이다.
1 | |
KMP 알고리즘은 중복해서 검사하는 인덱스가 없다. 따라서 시간복잡도는 O(N+M)가 된다.
복잡한 개념에 비해 코드는 상대적으로 간단하다. KMP 알고리즘이 쉬운 알고리즘은 아니라 필자도 코드를 먼저 익히고 각 코드가 어떤 의미를 갖는지를 분석하면서 KMP에 대한 개념을 어렴풋이 이해할 수 있었고 이 글을 쓰면서 조금 더 명확히 정리했다.
아마 이 글을 읽는 여러분들도 설명만 읽고는 명확히 KMP를 이해하기는 어려울 거라 생각된다. 따라서 스스로 고민하고 분석하는 시간을 가져 보는것이 좋을 듯 하다.